How LLMs Work in Search: A simple overview
Every time you ask ChatGPT, Perplexity, or Google's AI Overview a question, the answer you get back is generated one word at a time. Not retrieved from a database. Not copied from a webpage. Predicted. Understanding how LLMs work in search is now a prerequisite for anyone who wants their content to show up in AI generated answers, not just traditional blue links.
This matters because the shift from ten blue links to a single synthesized answer changes the economics of organic traffic. You are no longer competing for a position on a page. You are competing for a share of the answer itself. And the mechanics behind that answer, from next word prediction to retrieval augmented generation, dictate exactly what you need to do differently.
Related Readings:
- Generative engine optimization: the evolution of SEO and AI
- Generative engine optimization services
- How to rank on ChatGPT guide
- Semantic SEO AI strategies
- Semantic SEO services
- Generative Engine Optimization services
- The 9 best GEO tools
- AI Overviews explained
How LLMs Generate Answers: Next Word Prediction
Large language models do not "know" things the way a person does. They predict. Specifically, they predict the next most likely word (or token) based on patterns learned from massive training datasets.
Ask an LLM: "What is the best project management tool?" The model does not search a list of tools and compare features. It calculates probability distributions for what word comes next.
Based on patterns in its training data, it might predict:
The best project management tool is Jira (36% probability)
The best project management tool is Notion (27% probability)
The best project management tool is Trello (19% probability)
Those probabilities come from co occurrence patterns. During training, the model observed that certain brand names appear alongside certain descriptive phrases millions of times. Trello, for instance, frequently co occurs with phrases like "kanban style boards" and "visual project workflow." Jira co occurs with "agile sprint planning" and "enterprise development teams."
This is the foundation of how LLMs decide what to say about your brand, your product, or your category. The model has learned associations between your name and the concepts that surround it across the web. If your brand consistently co occurs with the problem you solve, in enough diverse contexts, the model assigns higher probability to mentioning you when that problem comes up.
The practical implication is straightforward. Co occurrence is not about a single ranking factor or a single page. It is about how often and in how many distinct contexts your brand appears alongside the language that describes your solution. A product page alone will not do it. You need mentions in reviews, forums, documentation, comparison articles, and community discussions. Each context reinforces the statistical association the model relies on.

How LLMs Work: Step-by-Step
User Prompt
↓
Tokenization → Semantic Embedding
↓
Search Intent + Entity Understanding
↓
Inference via Transformer Layers
↓
RAG, if needed → Injected into Prompt
↓
Next-Token Prediction + Scoring
↓
Answer Generation & Final Output
1. User Prompt
You provide an input: a question, instruction, or statement.
“What is the best SEO agency for SaaS companies doing 1.5M MRR?”
2. Tokenization → Semantic Embedding
The LLM breaks your text into tokens, which are then converted into embeddings, numerical vectors that represent the semantic meaning of each word.
These embeddings position the tokens in a multi-dimensional space, enabling semantic matching beyond keyword overlap.
Embedding-Based Retrieval vs Keyword Search
Traditional search matches queries to documents via keyword overlap. In contrast, LLMs convert both queries and documents into embeddings and retrieve information based on semantic similarity.
Example: A user asks, “Top SEO firms for SaaS startups.” The LLM may retrieve a page optimized for “best B2B SaaS SEO agencies” even if those exact words don’t appear because their embeddings are close in vector space.
3. Search Intent + Entity Understanding
The system classifies the user’s query by intent and extracts key entities.
Intent affects:
- Type of response (definition, recommendation, comparison)
- Retrieval strategy
- Output formatting
Entity extraction helps the model contextualize:
- “Best” = superlative intent
- “SEO agency” = category
- “1.5M MRR” = growth qualifier
Prompt Engineering & System Instructions
Behind the scenes, models are influenced by system prompts, invisible instructions that shape the tone, structure, and constraints of a response.
Examples:
- “Always cite your sources.”
- “Avoid controversial topics.”
- “Prioritize up-to-date information.”
Some LLMs like Claude and GPT-4o are instruction-tuned trained on thousands of example prompts/responses.
This means SEO isn’t just about the content you write, but how well it aligns with the model’s internal expectations and goals.
4. Inference via Transformer Layers
This is where the “thinking” happens. The Transformer architecture uses self-attention layers to model contextual relationships between tokens.
Each layer improves the model’s grasp of:
- Token dependencies
- Sentence structure
- Implicit meaning
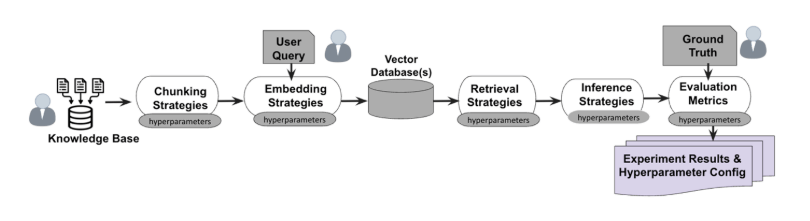
5. Retrieval-Augmented Generation (RAG)
If the LLM needs updated or specific data, it uses RAG to retrieve documents before generating an answer.
RAG Pipeline:
StepDescriptionQueryEmbed + fan-out your query into variantsRetrievePull matching docs from vector DBs or search APIsAugmentInject docs into the prompt contextGenerateUse prompt + docs to produce grounded output
To be cited in this process, format your content into clear, structured ~200-word chunks with headings, schema, and entities.
6. Next-Token Prediction + Scoring
LLMs predict the next token based on probabilities and continue recursively until the full response is built.
Exalt Growth [0.86], Skale [0.63], Growth Plays [0.57], etc.
7. Answer Generation & Final Output
Tokens are decoded into human-readable text and served to the user.
Applied Example
Query:
“Best CRM tools for startups 2025”
LLM Interprets:
- Intent: Comparative / decision-making
- Entities: CRM tools, startups, 2025
- Search strategy: Fan-out → retrieve feature tables, expert roundups
-
Content likely to be cited:
- Structured lists with schema
- 150–300 word sections
- Updated within the past 90 days
- Hosted on review sites or trusted blogs (G2, Forbes, niche SaaS sites)
How LLMs Work in Search with RAG
Pure next word prediction has a problem: the model's training data has a cutoff date. It cannot tell you about last week's product launch or yesterday's industry report. This is where retrieval augmented generation, or RAG, enters the picture.
RAG is the architecture that connects an LLM to live information. When you ask a question in an AI search experience, the system typically:
- Takes your query and searches the web (often through a traditional search engine like Bing or Google)
- Retrieves specific segments, blocks, or chunks from the top ranking pages
- Feeds those retrieved chunks to the LLM as context
- The LLM generates an answer using both its trained knowledge and the retrieved information
In this capacity, the LLM operates more as a reasoning and summarization tool than the creative generative model most people imagine. It is synthesizing retrieved information into a coherent response, not inventing from scratch.
Understanding how RAG works in search clarifies several things that matter for content strategy. First, AI search answers are only as good as the available data. If your product documentation is thin, ambiguous, or scattered, the model will either skip you entirely or fill in the blanks on its own. Not enough information is precisely when LLMs hallucinate. And the hallucinated version of your product will sound plausible, which makes it worse than being absent.
Second, RAG provides the mechanism for citations. When an AI search tool cites a source, it is pointing back to the specific chunk it retrieved. That chunk came from a page that ranked well enough in traditional search to be pulled into the retrieval pipeline. This is why AI search with LLM and RAG builds on traditional SEO rather than replacing it.
Third, RAG introduces a quality filter. The retrieval step can prioritize authoritative, well structured content and deprioritize thin or low quality pages. This means the bar for useful content goes up. You are not just trying to rank. You are trying to produce content that is worth retrieving.
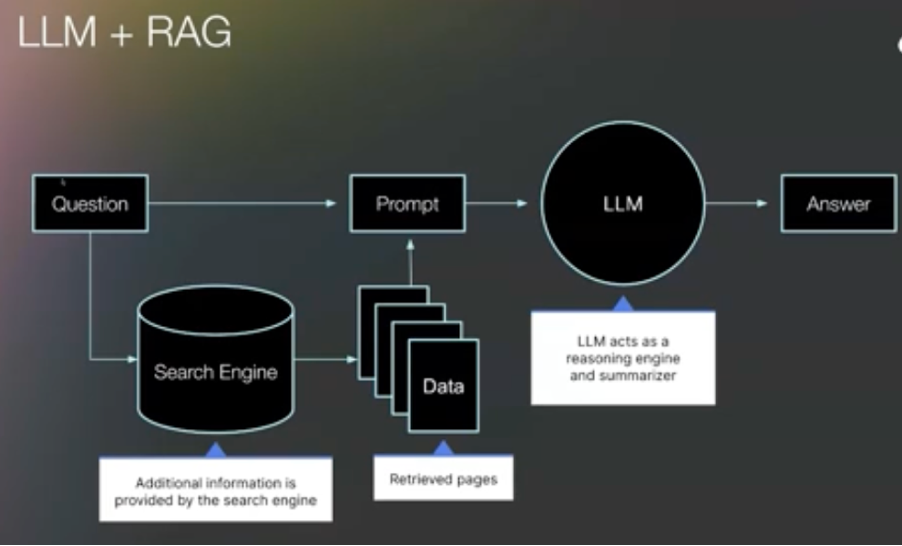
What RAG Means for Content Quality
RAG improves AI answers in four specific ways. It provides up to date information that the base model lacks. It creates an opportunity to filter out low quality or outdated sources. It constrains the LLM's creative tendencies, making answers more factual. And it facilitates source citation, connecting the generated answer back to the pages those chunks came from.
For content creators, this means comprehensive, well organized content that directly answers specific questions is more likely to be retrieved. Pages that cover a topic thoroughly, with clear structure and explicit answers to common questions, become the raw material the LLM draws from.
From Keywords to Questions: How Search Intent Changes with LLMs
Traditional SEO was keyword driven. You identified a target phrase, optimized a page around it, and tracked your ranking position. With LLMs in the mix, this model breaks down in important ways.
People interact with AI search differently than they interact with a search box. They ask full questions, often with nuance. And the same underlying intent can be expressed in many different ways:
"What is the best project management software?"
"Which project management tool is considered best?"
"Can you suggest the best project management software for teams?"
"What is the top rated project management software?"
"Which project management software offers the best features and usability?"
Each of these variations can produce a different answer. The LLM's response shifts based on the specific framing, the emphasis words, and the implied context. AI optimization varies by question form, which means a single optimized page targeting one keyword phrase is no longer sufficient.
This is why keyword research is becoming question research. Instead of identifying the highest volume phrase and building a page around it, you need to map the full landscape of questions people ask about your topic. How questions, what questions, when questions, can questions. The goal is to summarize and synthesize all the possible questions a searcher might ask and ensure your content addresses them.
Keyword difficulty becomes question difficulty. Some questions have well established consensus answers that are hard to displace. Others sit in gaps where no authoritative source has provided a clear, direct response. Those gaps represent the highest opportunity for earning a spot in AI generated answers.
Topical authority is what ties this together. LLMs assess whether a source has broad, deep coverage of a subject area, not just a single well optimized page. A site that answers every plausible question about a topic with comprehensive, unique content signals authority at the topic level. That signal influences which sources get retrieved and cited.
Share of Answer: The New Ranking Metric
In traditional SEO, you track position. You are number three for "project management software" or you are in the local pack for "CRM tools for startups." The metric is a single number tied to a single query.
AI search does not work that way. There is no fixed position in a generated answer. Your brand might be mentioned first in one response, third in another, and absent in a third, even for the same question asked seconds apart. The output is probabilistic, not deterministic.
This is why the industry is shifting from SERP position tracking to share of answer tracking. Instead of a single ranking, you measure a distribution. The percentage of times your brand is mentioned when a relevant question is asked. Share of voice in the AI answer space.
Effective share of answer tracking requires three dimensions:
Track by surface
The same question produces different answers on different platforms. Google AI Overviews, ChatGPT, Perplexity, Bing Copilot, and Claude all draw from different data sources and apply different retrieval logic. You need to ask the question across multiple surfaces to understand your true visibility.
Track by variation
Because AI optimization varies by question form, you cannot rely on a single phrasing. Ask the same underlying question in five, ten, or twenty different ways. Each variation tests a different slice of the model's probability distribution.
Track by run
LLM outputs are non deterministic. The same question on the same surface can produce different answers on different runs. Re ask the same questions multiple times and average the results. This gives you a statistically meaningful picture rather than a snapshot that could be an outlier.
The result is not a rank. It is a percentage. A share. How often you are mentioned, how prominently, and across which surfaces and question framings. This is the metric that replaces position tracking in an AI search world.
How to Optimize for LLMs in Search
Answer engine optimization, or AEO, is the practice that emerges from everything above. It is not a replacement for SEO. It is a layer on top of it, informed by how LLMs actually generate and retrieve answers.
Start with Co-occurrence
LLMs learn through co occurrence relationships. The more frequently your brand appears alongside the language of your solution category, across diverse and authoritative contexts, the stronger the statistical association the model builds.
This is not something you achieve with a single campaign or a single page. It requires showing up in many different places. Product pages, documentation, comparison articles, industry publications, community forums, and user generated content platforms like Reddit and Quora all contribute to the co occurrence patterns the model learns from.
Answer optimization also varies by surface. The content that influences Google AI Overviews differs from what influences ChatGPT, which differs from what shapes YouTube or social media AI features. Each surface draws from its own data ecosystem.
Build for Retrieval
Since RAG powered search starts with a traditional web search, your content needs to be findable and structured for retrieval.
This means:
Clear, direct answers to specific questions placed prominently in your content. Retrieval systems favor chunks that contain an explicit answer, not chunks that require the reader to infer one.
Comprehensive coverage that anticipates follow up questions. If someone asks about your product category, the retrieved page should address the what, how, when, and why in enough depth that the LLM can construct a full answer from it.
Unique information that differentiates your content from what already exists. If your page says the same thing as ten other pages, the retrieval system has no reason to prefer yours. Original research, proprietary data, and distinct frameworks give the LLM a reason to pull from your content specifically.
Optimize Citations: Owned and Earned
Citation optimization starts with SEO. AI search is backed by traditional search engines, and the pages that get cited are the pages that get retrieved, which are the pages that rank.
Citations in AI search come in different forms. Some appear at the end of the answer as a source list. Some appear inline, woven into the text of the response. Some sit below the fold where fewer users scroll. Each placement likely carries a different click through rate, similar to how position one through ten carry different CTRs in traditional search.
Tracking owned citations means monitoring how often your own content is cited across LLM answers. Apply the same three tracking dimensions: track by surface, by variation, and by run. This gives you a picture of which content assets earn citations, for which questions, and on which platforms.
But brands also need to earn citations from third party sources. When an industry publication or a review site mentions your product and that page gets retrieved by an AI search system, your brand appears in the answer even if your own pages were not directly cited. This is the earned side of citation strategy, and it connects directly to digital PR, partnerships, and community engagement.
UGC and Community Presence
User generated content on platforms like Reddit and Quora plays a specific role in LLM training and RAG retrieval. These platforms are heavily represented in training datasets, and their content frequently appears in AI search results.
A genuine community presence, where real users discuss and recommend your product, reinforces the co occurrence patterns that influence LLM outputs. This is not about astroturfing or seeding promotional content. It is about ensuring that your product is part of authentic conversations in the spaces where LLMs draw their information from.
What This Means for Your SEO Strategy
The core mechanics are simple. LLMs predict the next word based on co occurrence patterns. RAG connects those predictions to live, retrieved information.
The combination means AI search builds on traditional SEO rather than replacing it, but it demands a broader, more question oriented content approach.
The shift from tracking a single ranking to tracking share of answer changes how you measure success. The shift from keyword research to question research changes how you plan content. And the shift from page level optimization to topic level authority changes how you structure your entire content program.
Good content in this context means content that answers every relevant question comprehensively and uniquely. Not just the primary query, but the variations, the follow ups, and the related questions that a thorough searcher would ask. That depth, combined with broad co occurrence signals across diverse platforms, is what positions a brand to show up consistently in AI generated answers.
Where LLMs Access Web Content

Citation Trends: Which Sources Win?
Profound’s analysis of 30 million citations across ChatGPT, Google AI Overviews, Perplexity, and Microsoft Copilot revealed:
ChatGPT: Top 10 Cited Sources by Share of Top 10 (Aug 2024 – June 2025)
Table: Perplexity: Top 10 Cited Sources by Share of Top 10 (Aug 2024 – June 2025)

B2B SaaS Review Citations
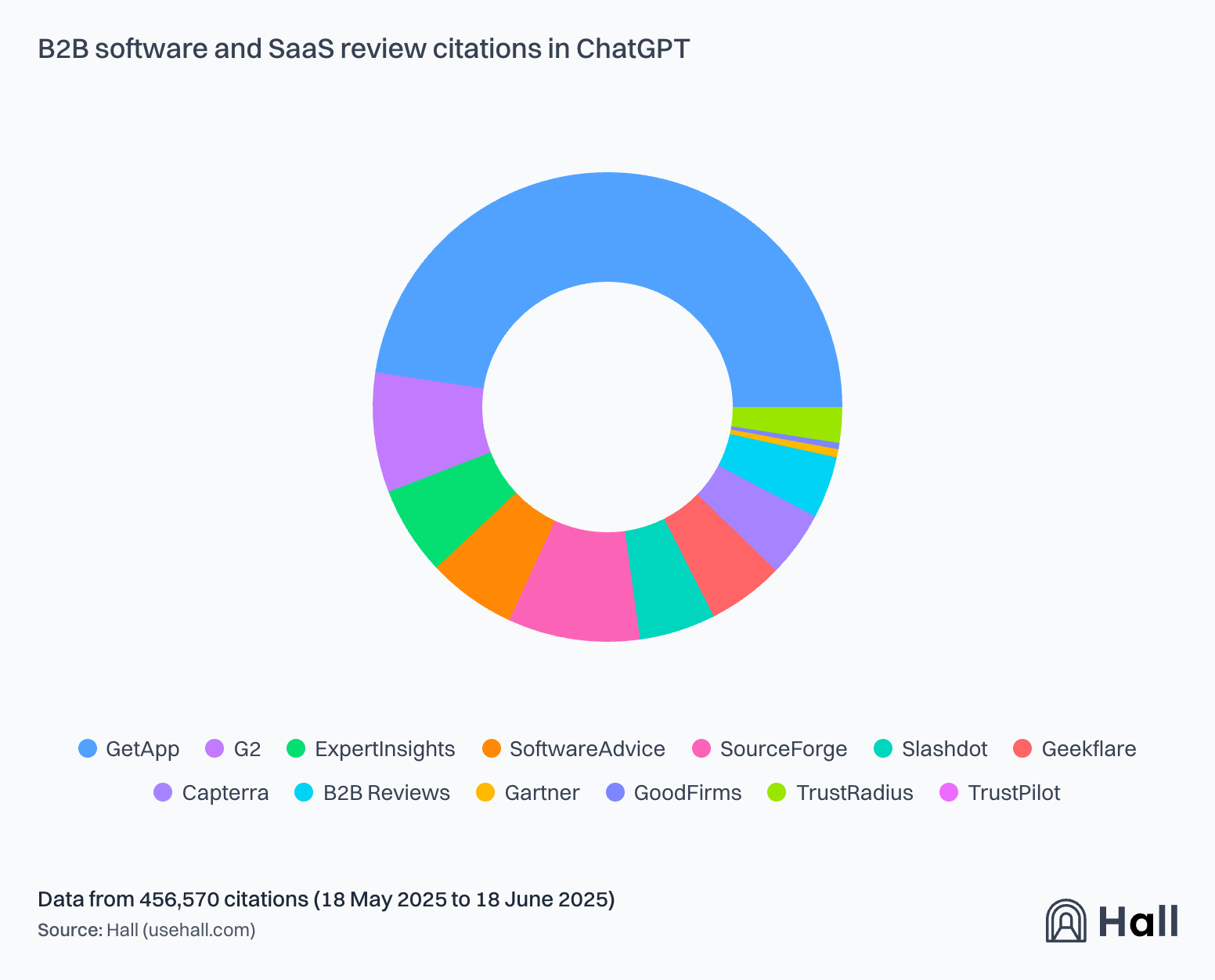
Key takeaways
- Industry-specific platforms consistently outperform generalist sites
- AI crawler policies directly impact visibility
- Different AI platforms favor different sources
- Citation trends remain highly dynamic
LLM Stage → SEO Implication Mapping
Limitations of LLMs
- Hallucinations: Incorrect facts or made-up citations
- Stale knowledge: Unless RAG is used
- Opaque ranking: Output depends on invisible system prompts
- Citation bias: Prefers mainstream, popular, and structured sources
Structuring Content for AI Retrieval
Best Practices:
- Chunk pages into 150–300 word blocks
- Use H2/H3s with clear topic labeling
- Include FAQPage, HowTo, WebPage, and Product schema
- Add anchor links and clear markup
- Host on high-authority domains
What’s Next for AI Search?
- Multimodal retrieval: Gemini and GPT-4o will increasingly cite videos and images
- Personalized memory: AI Mode and ChatGPT memory will tailor retrievals to user history
- Direct ingestion APIs: Some models may bypass search altogether and index private databases
- On-device LLMs: Future models may retrieve and process content offline or in edge settings
Glossary
- Tokenization: Breaking text into word-like units
- Embedding: Numeric representation of text meaning
- Entity: Recognized concept (e.g., “Exalt Growth”)
- Prompt: The input to the model
- RAG: Retrieval-Augmented Generation, using search before generating
FAQs
How do LLMs generate search answers?
LLMs generate answers through next word prediction. The model calculates the probability of each possible next word based on patterns learned during training, then selects words sequentially to build a complete response. In search contexts, this prediction is augmented with retrieved web content through RAG.
What is RAG and why does it matter for search?
RAG stands for retrieval augmented generation. It is the architecture that connects an LLM to live web data by retrieving relevant content chunks from indexed pages and feeding them to the model as context. RAG matters because it allows AI search to provide current, cited answers rather than relying solely on the model's training data.
Does traditional SEO still matter with AI search?
Yes. AI search systems typically use traditional search engines as the retrieval layer in their RAG architecture. Pages need to rank well in conventional search to be retrieved and cited in AI generated answers. Traditional SEO is the foundation that AI search optimization builds on.
How is optimizing for RAG different from traditional SEO?
Optimizing for RAG requires content that provides clear, direct answers in retrievable chunks. While traditional SEO focuses on page level ranking signals, RAG optimization prioritizes comprehensive question coverage, structured content that can be extracted in meaningful segments, and unique information the LLM cannot find elsewhere.
What is share of answer and how do you track it?
Share of answer is the percentage of times your brand appears in AI generated responses to relevant questions. You track it across three dimensions: by surface (different AI platforms), by variation (different phrasings of the same question), and by run (repeated queries to account for non deterministic outputs). The result is a distribution rather than a single ranking number.
Why do different question phrasings produce different AI answers?
LLMs are sensitive to the specific words and framing of a query. Different phrasings activate different probability distributions in the model, which can surface different co occurrence patterns and retrieve different content chunks. This is why question research across multiple variations matters more than targeting a single keyword phrase.
What is answer engine optimization (AEO)?
AEO is the practice of optimizing content to appear in AI generated answers rather than just traditional search results. It encompasses co occurrence optimization, RAG friendly content structure, question coverage, citation optimization, and share of answer tracking. AEO layers on top of traditional SEO rather than replacing it.
How do co occurrence patterns affect LLM mentions?
Co occurrence is the statistical relationship between words that frequently appear together in training data. When your brand consistently appears alongside language that describes your solution category across many diverse contexts, LLMs build stronger associations and are more likely to mention your brand when generating answers about that category.
Can you optimize for specific AI search platforms?
Each AI search platform draws from different data sources and applies different retrieval logic. Google AI Overviews rely on Google's index. ChatGPT may use Bing. Perplexity has its own retrieval pipeline. Effective optimization requires understanding which content ecosystem each surface draws from and tailoring your presence accordingly.
How does user generated content influence AI search results?
Platforms like Reddit and Quora are heavily represented in LLM training data and frequently appear in RAG retrieval results. Authentic discussions about your product on these platforms reinforce the co occurrence patterns that influence LLM outputs. A genuine community presence contributes to your brand's visibility in AI generated answers.