Entity SEO for SaaS: Build the Architecture That Gets Cited
Most SaaS companies treat entity SEO as a schema markup exercise. Add some JSON-LD. Tag the Organization. Move on.
That approach misunderstands what entities actually do inside modern search and AI systems.
Entities are the primitive unit of machine reasoning. They are what search engines, knowledge graphs, and large language models use to decide which brands exist, what they do, and whether they deserve to be cited.
When ChatGPT recommends a project management tool or Google AI Mode composes an answer about asset tracking software, the selection process runs through entities. Not keywords or domain authority scores.
For SaaS companies competing in categories where AI platforms increasingly mediate buyer discovery, entity SEO is the architecture layer that determines whether your product gets mentioned at all.
This article explains how entity graphs feed both Knowledge Graph grounding and LLM parametric memory. It maps the specific entity hierarchy a SaaS company needs to build. And it introduces entity corroboration as a durable competitive moat that compounds over time.
Why Entities Are the Retrieval Primitive for AI Systems
The shift from keyword matching to entity understanding started over a decade ago when Google launched the Knowledge Graph. But its implications have accelerated dramatically with the rise of LLM-powered search.
Here is the core mechanic. When a user asks ChatGPT "What is the best SaaS tool for user research?" or queries Google AI Mode for "asset tracking software for construction," the system does not scan documents for matching strings. It resolves the query to entities: user research, SaaS, asset tracking, construction. Then it traverses relationships between those entities and candidate answers.
Research on Knowledge Graph-enhanced RAG systems confirms this pattern. Entity-level retrieval consistently outperforms passage-level retrieval for factual and compositional questions. When retrieval systems link content mentions to canonical entities before searching, answer accuracy improves measurably. The reason is simple. Embeddings retrieve semantic neighbors. Entity graphs retrieve logical dependencies.
This matters for SaaS companies because of how the retrieval layer connects to two distinct memory systems inside LLMs.
Grounded retrieval is what happens when an AI platform searches the live web, retrieves content, and constructs an answer from what it finds. Google AI Mode, Perplexity, and ChatGPT with search all use this mechanism. Your entity clarity determines whether your content survives the retrieval filter.
Parametric memory is what the model learned during training. When an LLM names your product without searching the web first, that is parametric recall. It selected your brand from patterns encoded during pretraining. Entity density across the web directly influences how deeply your brand gets encoded into those patterns.
Both systems reward the same thing: an unambiguous, well-corroborated entity with explicit relationships to the concepts a searcher cares about.
If your product is not clearly defined as an entity with attributes, relationships, and cross-source validation, you are invisible to both retrieval layers.
The Entity Signal Stack: What Gets Evaluated
Entity SEO is not a single optimization. It is a stack of signals that together determine how machines understand and trust your brand.
1. Semantic relevance
This is the foundation. Your entity needs to be semantically connected to the topics your buyers search for. This is not keyword density. It is conceptual proximity in an entity graph. A SaaS company selling compliance software needs its entity to sit close to regulatory concepts, audit workflows, and risk management in the machine's understanding of the world.
2. Source authority
This determines how much weight your entity carries. Authority in an entity context is not just domain rating. It includes the quality and diversity of sources that reference your entity. Mentions in industry publications, analyst reports, and peer platforms carry more weight than self-published content.
3. Entity relationships
These map how your brand connects to other known entities. Google's Knowledge Graph, Wikidata, and LLM training data all encode relationships. If your product is linked to a well-known category, a recognized founder, specific technology partnerships, or notable customers, those connections strengthen your entity's position.
4. Evidence density
This measures how much verifiable information exists about your entity. Named frameworks, published methodologies, specific data points, and documented outcomes all increase evidence density. Generic claims do not.
5. Structural accessibility
This determines whether machines can actually parse and extract your entity information. This is where schema markup, clean HTML structure, and content architecture converge. A page with proper JSON-LD, clear heading hierarchy, and atomic fact statements is structurally accessible. A wall of marketing copy is not.
6. Corroboration
This is the signal most SaaS companies overlook entirely. It measures whether independent sources agree on what your entity is and does. If your website says one thing, your Wikidata entry says another, and your Crunchbase profile says something else, corroboration fails. If all sources align and cross-reference each other, corroboration strengthens dramatically.
These signals do not operate in isolation, they compound. The compounding effect determines more than whether your brand appears. It determines how your brand appears. LLMs distinguish between mention and recommendation. A mention is background material. The AI names your product alongside five others without preference. A recommendation is an explicit citation with context, attributes, and positioning.
The difference is evidence weight. Brands with weak entity architecture get mentioned. Brands with strong corroboration, structured identifiers, and relationship density get recommended. For SaaS companies, the gap between mention and recommendation is the gap between appearing in a list and being the answer.

Monosemantic Content Engineering: Why Precision Determines Retrieval
Entity signals tell machines what to evaluate. Monosemanticity determines whether the evaluation returns a clear answer.
A monosemantic term has exactly one valid interpretation in context. "Salesforce" inside a CRM comparison is monosemantic. "Platform" on a SaaS homepage is not. It could mean software platform, integration platform, developer platform, or marketing platform. Every ambiguous term forces the retrieval system to guess. Guessing lowers confidence scores. Lower confidence means lower retrieval probability.
This matters at the embedding level. When your content uses a term with multiple valid meanings, the resulting embedding sits between clusters rather than inside one. A chunk describing your product as "the leading platform for teams" produces an embedding that is weakly similar to dozens of categories. A chunk describing your product as "the leading compliance automation tool for healthcare finance teams" produces an embedding that strongly matches a narrow, high-intent query space.
Monosemantic content earns higher cosine similarity scores against specific queries. Polysemic content earns moderate similarity scores against many queries but strong scores against none.
The practical consequence for SaaS companies is direct. Retrieval systems evaluate content at the chunk level. Each chunk competes independently. A single ambiguous paragraph can cause the retrieval system to skip your content even when the rest of the page is precisely defined.
Three Rules for Monosemantic SaaS Content:
1. Name the entity, not the category
Weak: "Our solution helps businesses manage their assets."Strong: "GoCodes is asset tracking software for construction, healthcare, and government organizations."
The first sentence could describe any of 200 SaaS products. The second produces an embedding that clusters tightly with high-intent queries about asset tracking in specific verticals. The entity (GoCodes), the function (asset tracking), and the audience (construction, healthcare, government) are all resolved.
2. Disambiguate through co-occurring entities
Isolated terms are polysemic. Terms surrounded by related entities become monosemantic.
"Workflow automation" alone is ambiguous. It maps to marketing automation, DevOps pipelines, HR onboarding, or document processing. Adding co-occurring entities resolves the ambiguity: "workflow automation for SOC 2 audit preparation, integrating with Vanta and Drata" pins the meaning to compliance automation. The retrieval system no longer has to guess which "workflow automation" you mean.
Every core product description should include at least three disambiguating entities: the product itself, the category it belongs to, and the adjacent products or concepts it relates to.
3. Front-load the disambiguating context
Retrieval systems chunk content into segments of 256 to 512 tokens. If your disambiguating entities appear in paragraph four but your opening paragraph uses only generic terms, the first chunk gets retrieved without context. The chunk that enters the scoring phase looks identical to every competitor's generic opening.
Place entity-specific, monosemantic language in the first 100 words of every page. Place it in the first sentence of every headed section. Place it in every H2 and H3. These are the positions most likely to anchor a chunk boundary.
Monosemanticity and the PoI Signals
Monosemantic content directly strengthens three of the seven Proof of Importance signals:
1. Semantic Relevance
Improves because unambiguous content produces tighter embedding matches against specific queries. A chunk with one valid interpretation scores higher than a chunk the retrieval system must disambiguate before scoring.
2. Entity Relationships
Strengthen because monosemantic content explicitly names the entities your brand connects to. Each named entity is a node in the relationship graph. Generic language leaves those nodes undefined.
3. Structural Accessibility
Improves because monosemantic content is easier for machines to parse into clean chunks. Ambiguous language creates chunks that require cross-reference with other chunks to resolve meaning. Self-contained, monosemantic chunks are independently retrievable.
The compounding effect is significant. Monosemantic content across your entity hierarchy means every layer (Organization, Product, Features, Use Cases, Integrations) produces precise, high-confidence embeddings. The retrieval system encounters your content and gets a clear answer at every level of query specificity.
Multimodal Entity Reinforcement
Entity architecture is not limited to text. Modern retrieval systems, particularly Google AI Mode running on Gemini, process text, images, and video within a shared embedding space. An image of your product interface and a text description of your product function can produce embeddings that cluster together, reinforcing the same entity from two modalities.
This has a direct implication for SaaS entity architecture. Product screenshots, feature demonstration videos, and branded diagrams are not just UX assets. They are entity signals. When a product screenshot includes visible UI elements that match your feature-level entities (a Gantt chart view, a compliance dashboard, an integration settings panel), the image embedding reinforces the text embedding for that feature entity. The retrieval system encounters converging evidence across modalities, which increases confidence in the entity match.
The practical minimum: every feature page and use case page should include at least one image that visually represents the entity defined on that page. The image alt text and surrounding caption should use the same monosemantic language as the page content. Schema markup should include image properties that connect the visual asset to the entity definition.
Cross-modal reinforcement is especially relevant for competitive queries where multiple SaaS products claim similar capabilities. Text-only entity definitions compete on semantic precision alone. Text-plus-image entity definitions compete on semantic precision and visual corroboration. The product that provides both gives the retrieval system a stronger, multi-signal match.
The SaaS Entity Hierarchy: Organization, Product, Features, Use Cases, Integrations
No existing guide maps the specific entity architecture a SaaS company needs. Most entity SEO content talks about entities generically. SaaS companies need a concrete hierarchy.
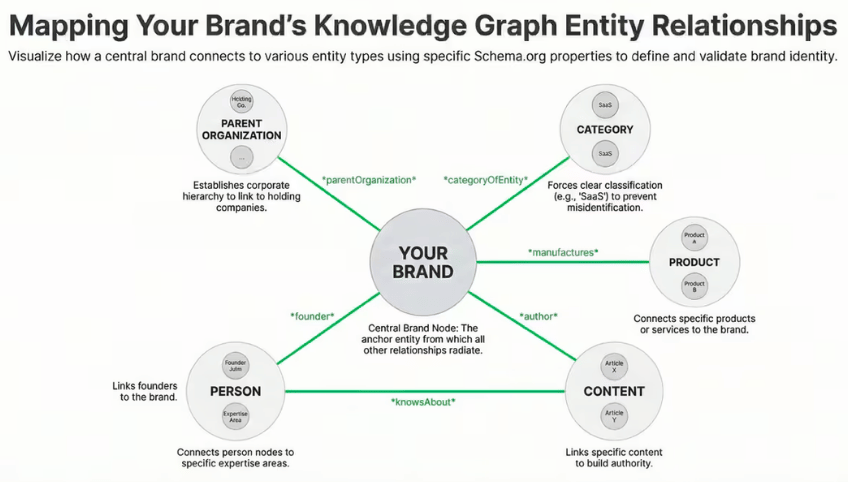
The entity stack for a SaaS company has five layers. Each layer contains entities that must be explicitly defined, properly related to the layers above and below, and consistently represented across all properties.
Layer 1: Organization (Schema: Organization)
This is your company entity. It includes your legal name, founding date, headquarters, founders, team members, and category. In schema terms, this is the Organization type with sameAs links to Wikidata, Crunchbase, LinkedIn, and other authoritative profiles.
Set an @id like https://yourdomain.com/#organization and reference it from every page.
The Organization entity anchors everything. If this layer is ambiguous, every entity below it inherits that ambiguity.
Layer 2: Product (Schema: SoftwareApplication)
Most SaaS companies are a single product. Some operate multiple products under one organization. Either way, each product needs its own entity definition. This includes the product name, category, primary function, target audience, and pricing model.
The Product entity should be typed as SoftwareApplication in schema with applicationCategory set to your software category. Link it upward to the Organization via publisher or provider and outward to the category it belongs to.
Layer 3: Features (Schema: DefinedTerm or PropertyValue)
Features are the atomic capabilities of your product. Each major feature is a sub-entity of the Product. A project management SaaS might have entities for task management, Gantt charts, resource allocation, and time tracking.
Use DefinedTerm with inDefinedTermSet linking back to the product, or PropertyValue within the product's additionalProperty array. Feature entities matter because they are what AI systems match against when users ask specific capability questions. "What SaaS tool has built-in Gantt charts?" triggers feature-level entity matching.
Layer 4: Use Cases (Schema: Service or WebPage with about)
Use cases map features to outcomes. They answer the question "what can I accomplish with this product?" Use case entities sit between features and buyer intent. They connect your product to the jobs buyers need done.
Type each use case page as a WebPage with an about property pointing to the relevant DefinedTerm entities, or use Service schema with serviceType and provider linking to your Organization. Each use case should have its own page, its own schema, and explicit relationships to both the features that enable it and the industries or roles it serves.
Layer 5: Integrations (Schema: SoftwareApplication with interactionService)
Integrations connect your product entity to other known product entities. When your SaaS integrates with Salesforce, Slack, or HubSpot, those are entity relationships to well-established nodes in the Knowledge Graph.
Use SoftwareApplication schema with isRelatedTo or interactionService pointing to the partner product's entity. Integration entities are high leverage because they borrow authority from established entities. A SaaS tool that is explicitly linked to Salesforce inherits some of Salesforce's entity strength.
Why This Hierarchy Matters for AI Retrieval
AI systems do not understand your product as a monolith. They decompose it into entity components and evaluate each one against the query context. A buyer asking about "compliance software for healthcare" triggers matching at the use case level. A buyer asking about "tools that integrate with Salesforce" triggers matching at the integration level.
If your entity hierarchy is flat or missing layers, you lose these specific matching opportunities. Your product might be the right answer, but the machine cannot confirm it because the entity structure is incomplete.
Entity disambiguation is the direct outcome of this hierarchy. When two SaaS products have similar names or overlapping categories, the one with a richer entity hierarchy is easier for machines to disambiguate. The product with clearly defined features, use cases, and integrations gets recommended. The one without gets confused with competitors.
Entity Corroboration: The Competitive Moat Nobody Talks About
Entity corroboration is the most underrated concept in entity SEO. It is also the hardest for competitors to replicate.
Corroboration measures whether multiple independent sources agree about your entity. It goes beyond just having mentions. It requires that those mentions are consistent, specific, and cross-referenced.
The sameAs Chain
At the technical level, corroboration starts with sameAs links in your schema markup. When your Organization schema includes sameAs references to your Wikidata entry, LinkedIn company page, Crunchbase profile, and other authoritative sources, you are telling machines: "These are all the same entity."
But sameAs only works if those destinations actually exist and contain consistent information. An empty Wikidata entry or a Crunchbase profile with outdated information weakens rather than strengthens corroboration.
Wikidata as an Anchor Node
Wikidata deserves special attention because it functions as a neutral, machine-readable knowledge base that both Google's Knowledge Graph and LLM training pipelines consume directly. Having a well-maintained Wikidata entry for your organization (and ideally your founder) creates an anchor node in the global entity graph.
A Wikidata entry should include your entity type (instance of: software company), founding date, headquarters, official website, founders, and product descriptions. Each property should have references. Each claim should be sourced.
Bidirectional Linking
One-directional sameAs links create weak corroboration. Bidirectional linking creates strong corroboration.
This means your website links to your Wikidata entry via sameAs. Your Wikidata entry links back to your website via the official website property. Your Crunchbase profile links to your website. Your LinkedIn page links to your website. And your schema markup references all of these.
When a machine encounters your entity across multiple sources and every source agrees on what you are and points to the others, confidence in your entity increases. This is the same principle that makes Knowledge Graph panels appear in search results.
Sufficient corroboration triggers machine confidence and the impact is measurable. Sources with stable entity identifiers (Q-IDs, sameAs links, consistent @id references) receive an estimated 2 to 3x higher weight in LLM evidence scoring compared to unstructured sources covering the same topic.
This multiplier compounds across the corroboration stack. A single sameAs link adds some weight. A full bidirectional chain with Wikidata anchoring, consistent @id patterns, and third-party corroboration stacks that multiplier across every retrieval event.
Why Corroboration Is a Moat
Corroboration compounds over time and is expensive for competitors to replicate. Building a well-sourced Wikidata entry requires notability and verifiable references. Establishing consistent cross-platform entity definitions requires coordination across every property. Earning independent third-party mentions that corroborate your entity claims requires genuine authority.
A competitor can copy your content. They cannot copy your entity corroboration stack. Every additional corroborating source, every third-party mention that validates your entity claims, and every maintained cross-reference strengthens a position that takes months or years to build.
Practical Entity Architecture for SaaS Companies
Building entity architecture is not theoretical. It requires specific implementation steps.
Audit your current entity state
Query ChatGPT, Perplexity, and Google AI Mode about your product category. Does your product appear? Is it described accurately? Are the right features and use cases attributed to you? If the AI platforms confuse your product with a competitor or describe you inaccurately, your entity architecture has gaps.
Build your schema stack
Implement JSON-LD across your site with a full @graph structure. Organization on every page. SoftwareApplication on your product page. Service schemas on service pages. FAQPage on pages with questions. Each schema should include sameAs links to all your authoritative properties. Aggregate those page-level entities into a site-wide entity map so AI systems read one declared graph.
Create or update your Wikidata entry
Ensure it has verifiable references, complete properties, and bidirectional links to your website. If your founder has sufficient notability, create a separate Person entry linked to the Organization.
Map your content to entity layers
Every major feature should have a page. Every primary use case should have a page. Every significant integration should have a page. Each page should contain structured data that explicitly connects it to the Product and Organization entities above it.
Establish internal entity linking
Your internal links should follow entity relationships, not just topical relevance. Feature pages link to the use cases they enable. Use case pages link to the integrations that support them. Everything links back to the product. This creates a navigable entity graph that mirrors how machines traverse relationships. Publishing that graph as an entity map makes the relationships explicit to AI consumers.
Monitor your entity in AI systems
Track how AI platforms describe your product using tools like Hall or Goodie AI. Set up test queries that probe your entity at each layer: organization, product, features, use cases, integrations. When a layer returns inaccurate or missing information, you know where your entity architecture needs work.
Entity SEO Is Not a One-Time Project
Entity architecture pays returns on two time axes simultaneously. The transient return is immediate. When an AI platform searches the web and encounters your JSON-LD, your sameAs links, and your @id anchors, it reads them in real time.
That structured data influences the evidence weighting for the current query. Your entity clarity shapes the answer being constructed right now. The persistent return compounds over months. Structured data that remains stable across crawl cycles gets absorbed into future training runs. Your entity relationships, your Wikidata properties, and your schema definitions become part of the model's parametric memory.
The LLM cites your product from internal knowledge, without needing to search the web at all. This dual return is why entity architecture outperforms content volume as a long-term investment. Content decays. Entity infrastructure accumulates.
Ongoing maintenance ensures your entity stays accurate, corroborated, and connected as your product evolves. When you ship a new feature, it needs an entity definition. When you enter a new market, your use case layer needs expansion. When a third-party publication mentions your product, that mention should be cited in your Wikidata entry as a reference.
The SaaS companies that build and maintain entity architecture now will have a structural advantage as AI-mediated discovery becomes the default buyer path. Their products will be cited. Their competitors will be invisible.
Search has moved from ranking pages to retrieving entities to composing answers. Entity architecture determines who gets composed.
Frequently Asked Questions
What is entity SEO?
Entity SEO is the practice of optimizing how search engines and AI systems understand your brand as a distinct, identifiable entity. It involves defining your organization, products, and relationships using structured data, knowledge graph entries, and cross-source corroboration so that machines can confidently retrieve and cite your content.
How is entity SEO different from traditional keyword-based SEO?
Traditional SEO matches keywords on pages to search queries. Entity SEO defines your brand as a recognized object in knowledge graphs and AI training data. Keywords target search queries. Entities target machine understanding of what your brand is, what it does, and how it relates to other concepts.
Why do SaaS companies specifically need entity SEO?
SaaS companies compete in categories where AI platforms increasingly mediate buyer discovery. When a buyer asks ChatGPT or Google AI Mode for product recommendations, the system selects entities, not pages. SaaS companies without clear entity architecture get skipped in favor of competitors whose entities are well-defined.
What is entity corroboration?
Entity corroboration measures whether multiple independent sources agree about your entity. It requires consistent information across your website, Wikidata, Crunchbase, LinkedIn, and other authoritative profiles. Strong corroboration increases machine confidence in your entity and improves your chances of being cited.
How does schema markup relate to entity SEO?
Schema markup provides machine-readable entity definitions on your website. It tells search engines and AI crawlers what type of entity you are, what your attributes are, and how you relate to other entities. Schema is the structural layer that makes your entity accessible to machines.
What role does Wikidata play in entity SEO?
Wikidata functions as a neutral, machine-readable knowledge base consumed by Google's Knowledge Graph and LLM training pipelines. A well-maintained Wikidata entry creates an anchor node in the global entity graph, strengthening your entity's presence across AI systems.
Can small SaaS startups benefit from entity SEO?
Yes. Entity SEO favors clarity over size. A small SaaS company with a well-defined entity hierarchy, strong corroboration, and rich structured data can outperform a larger competitor with a weak or ambiguous entity presence. Entity architecture rewards precision.
How do I measure entity SEO performance?
Monitor how AI platforms describe your product using AI visibility tracking tools. Set up test queries at each entity layer: organization, product, features, use cases, and integrations. Track whether your product appears, whether descriptions are accurate, and whether you are recommended in relevant category queries.
What is the difference between topical authority and entity authority?
Topical authority is a content volume metric. Entity authority measures how completely and consistently your brand is defined within knowledge graphs. A company with 50 blog posts and weak entity structure has topical authority. A company with 10 well-structured pages and strong corroboration has entity authority. AI systems reward the latter.
How long does it take to build entity architecture for a SaaS company?
Initial entity architecture can be implemented in 4 to 8 weeks. This includes schema deployment, Wikidata entry creation, content mapping, and internal entity linking. However, entity architecture is infrastructure, not a campaign. Ongoing maintenance and expansion are required as your product evolves.
What is monosemantic content?
Monosemantic content uses language with a single valid interpretation in context. Instead of generic terms like "platform" or "solution," monosemantic content names specific entities, functions, and audiences so retrieval systems can match it to precise queries without disambiguation.
How does multimodal content affect entity SEO?
Modern AI systems process text and images in a shared embedding space. Product screenshots, feature videos, and branded diagrams produce image embeddings that reinforce text-based entity definitions. Pages with both text and visual entity signals provide stronger retrieval matches than text-only pages.

