What Content Gets Cited in AI Search for B2B SaaS
You can publish a 5,000 word guide, hit position one on Google, and still get zero citations from ChatGPT. That disconnect is the central challenge of AI search optimization: the signals that drive traditional rankings and the signals that drive LLM citations overlap in some places and diverge completely in others.
New research is starting to quantify exactly what earns a citation in AI search. The data reveals patterns that most SEO teams are not yet acting on. Some of those patterns are intuitive. Others contradict years of received wisdom about domain authority, content length, and structured data.
This article breaks down what we know about citations in AI search, drawn from empirical research on ChatGPT recommendation behavior, entropy reduction theory in language models, and competitive SERP analysis across the topic space. If you are building a content strategy for AI visibility, these are the mechanics you need to understand.
Related readings:
How ChatGPT Decides What to Cite
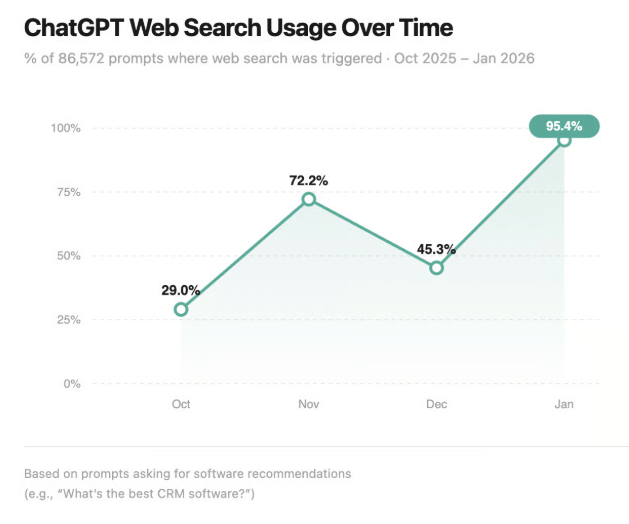
ChatGPT does not browse the web the way a human does. When it processes a query that triggers web search (which now happens 95.5% of the time for B2B software prompts, up from 29% in October 2025), it pulls content through a retrieval augmented generation pipeline. The model retrieves candidate documents, processes them, and then generates its response while citing sources.
The question is: what determines which retrieved documents actually influence the response?
The answer starts with a concept called entropy reduction. Language models generate text by predicting the next token in a sequence. When the model encounters content that reduces uncertainty about what comes next, that content becomes more useful to the generation process. High entropy content, where many plausible continuations exist, gets deprioritized. Low entropy content, where the next token is highly predictable given the context, gets favored.
This has practical implications. Content that presents information in self contained, clearly structured units gives the model less ambiguity to resolve. A well formatted list of SaaS pricing models with defined characteristics is lower entropy than a rambling narrative that discusses pricing philosophy across twelve paragraphs. The model can extract and cite the list. It struggles to extract a coherent claim from the narrative.
Think of it this way: LLMs are not evaluating content quality the way an editor would. They are evaluating content utility for their immediate generation task. The content that wins is the content that makes the model's job easier.

The Data Behind Brand Mentions in LLMs
Recent analysis of ChatGPT recommendation behavior across B2B software categories has quantified the relationship between cited URLs and brand recommendations. The findings give us the clearest picture yet of how citations in AI search translate into commercial outcomes.
The headline number: 92.7% of brands that ChatGPT recommends appear in the URLs the model cites during its response. This means that for the vast majority of recommendations, the model is not pulling from training data or general knowledge. It is pulling from the specific web pages it retrieves in real time.
That changes the optimization calculus entirely. You are not competing against what the model "knows." You are competing for presence in the set of documents the model retrieves for a given query.
Quantity of Citations Creates a Compounding Effect
The research found a stark threshold effect. Brands that appear in six or more cited URLs are roughly six times more likely to be recommended than brands appearing in fewer citations. This is not a linear relationship. There is a clear inflection point where citation volume tips into recommendation probability.
For content strategists, this means that a single well ranking page is not enough. You need multiple pages across your domain (and ideally third party domains) that the model can retrieve for relevant queries. Topical coverage depth matters more than any individual piece of content.
Position Matters, But Not the Way You Think
A regression analysis of brand position within cited content found that 31% of recommendation variance is explained by where the brand appears in the cited pages. Another 35% is explained by the sheer quantity of citing URLs. Combined, position and quantity account for the majority of recommendation likelihood.
But here is the nuance: peak position outperforms average position as a predictor. That means a brand that appears first in one cited document and fifth in another performs better than a brand that consistently appears third across all cited documents. One strong signal beats consistent mediocrity.
The practical takeaway: optimize your most important content to mention your brand or product as early and prominently as possible. Do not spread your positioning evenly across all content. Concentrate it.
What Content Format Wins in AI Search
Not all content types perform equally in retrieval augmented generation. The format of your content needs to match the query type the model is trying to answer.
Categorical Queries Favor Structured Content
When a user asks ChatGPT something like "best project management tools for startups" or "types of SaaS pricing models," the model is looking for content it can enumerate. Lists, tables, comparison matrices, and structured breakdowns win for these queries because they present information in discrete, extractable units.
This is where entropy reduction becomes visible. A bulleted list of five pricing models with two sentence descriptions gives the model exactly what it needs. Each item is a low entropy unit. The model can cite the source, extract the relevant items, and generate its response with high confidence.
If your content covers categorical topics but presents everything in flowing prose, the model has to work harder to identify the boundaries between items. That extra processing cost makes your content less useful to the model, and less likely to be cited.
Relational Queries Favor Narrative Depth
Conversely, when users ask questions like "why do PLG companies struggle with enterprise sales" or "how does AI search change content strategy," the model needs connected reasoning. For these queries, narrative content that builds an argument with evidence, examples, and causal logic tends to outperform listicles.
The key is that your narrative still needs to be structured. Clear paragraphs that each make one point. Explicit topic sentences. Logical flow from claim to evidence to implication. The model needs to follow your reasoning chain and reproduce it. If your argument requires reading between the lines, the model will reach for a source where the reasoning is more explicit.
The JSON LD Misconception
A common belief in the SEO community is that schema markup and JSON LD structured data help content surface in AI search. The evidence does not support this for the generation phase. JSON LD exists in the page source and may help upstream retrieval systems identify relevant content, but once content enters the generation pipeline, the model works with text. It does not parse schema markup to determine what to cite.
This does not mean you should remove your structured data. It still has value for traditional search and may play a role in retrieval. But adding more JSON LD to your pages will not directly improve your citation rate in AI generated responses.
Optimizing for RAG: What Actually Moves the Needle
Retrieval augmented generation is the pipeline through which your content enters AI search results. Optimizing for RAG means optimizing for two stages: getting retrieved, and getting cited once retrieved.
Stage 1: Getting Retrieved
Retrieval relies on semantic similarity between the user's query and your content. This is where traditional SEO and AI search optimization converge. If your content ranks well in Google, it is more likely to be in the candidate set that ChatGPT retrieves. The 95.5% web search rate means the model is actively pulling from live search results for almost every query.
To maximize retrieval probability:
- Write content that directly addresses specific queries rather than broad topics. A page titled "How to Price a PLG Product" will be retrieved for that query more reliably than a general guide to SaaS pricing that happens to cover PLG in one section.
- Publish across multiple relevant queries. Since citation quantity drives recommendations, you need content that gets retrieved for variations of your target topics. Cover the same theme from different angles across multiple pages.
- Build third party presence. Content on your own domain is not enough. Guest posts, product listings, review sites, and industry publications that mention your brand all contribute to the citation count that drives recommendations.
Stage 2: Getting Cited Once Retrieved
Being retrieved is necessary but not sufficient. The model still needs to select your content for citation over other retrieved candidates. This is where content structure becomes critical.
Self contained sections with clear headings allow the model to extract relevant passages without losing context. If your key insight is buried in the middle of a 3,000 word page with no subheadings, the model may retrieve the page but cite a competitor whose content is easier to parse.
Concrete, specific claims outperform vague assertions. "Companies using usage based pricing see 15% higher net revenue retention" is citable. "Usage based pricing can improve retention metrics" is not distinctive enough to cite over other sources making similar claims.
Factual density matters. Pack your content with specific data points, named examples, and defined frameworks. Each of these creates a low entropy anchor that the model can reference with confidence.
The Domain Authority Myth in AI Search
One of the most significant findings from entropy reduction research is that domain authority, the metric that has governed traditional SEO strategy for years, does not function the same way in AI search.
In traditional search, Google uses link signals and domain level trust metrics to rank content. A page on Forbes.com about SaaS pricing will typically outrank the same quality content on an unknown blog, purely because of domain authority.
LLMs do not have an equivalent mechanism during generation. The model evaluates content based on its utility for the current generation task, not based on the reputation of the source domain. A niche blog with exceptionally well structured, specific content about B2B pricing can outperform a high authority domain that covers the same topic superficially.
This is why smaller SaaS companies can compete effectively in AI search even when they cannot compete in traditional organic rankings. The playing field is structured differently. Content quality, specificity, and structure matter more than link profiles and domain metrics.
That said, domain authority still influences retrieval. If the model uses Google search results to build its candidate set, high authority domains have an advantage at the retrieval stage. But once content is retrieved, the playing field levels based on content structure and relevance.
Building a Citations in AI Search Strategy
Putting this research together, an effective strategy for earning citations in AI search looks different from a traditional SEO playbook.
Map Your Citation Landscape
Before creating content, understand where your brand currently appears in AI search responses. Run the prompts your target audience would use and document which brands get cited, how often, and in what position. This gives you a baseline and identifies the specific queries where you need to build presence.
Prioritize Topical Coverage Over Individual Rankings
The data shows that citation quantity is the strongest predictor of recommendation. Instead of optimizing one page to rank first, build a cluster of content across your domain and third party sites that covers your topic from multiple angles. Each piece should target a specific query variation and be structured for easy extraction.
Structure Content for the Model, Not Just the Reader
Every page should have clear H2 and H3 hierarchy, self contained sections, and explicit topic sentences. For categorical topics, use lists and tables. For relational topics, write clear argumentative prose with one claim per paragraph.
Front load your key points. The model scans for relevant passages, and content that appears early in a document gets weighted more heavily. Put your most important insights, data points, and brand mentions in the opening sections.
Invest in Factual Density
The scarcest resource in AI search is not content volume. It is content that contains specific, citable claims backed by evidence. Every piece you publish should include original data, concrete examples, named frameworks, or specific numbers. These are the low entropy anchors that models gravitate toward.
Monitor and Iterate
AI search behavior is evolving rapidly. ChatGPT's web search usage jumped from 29% to 95.5% in just a few months. The models, retrieval mechanisms, and citation patterns will continue to shift. Build a monitoring cadence that tracks your citation presence across key queries monthly and adjusts your strategy based on what the data shows.
What Comes Next for AI Search Citations
The optimization window for AI search is still early. Most content teams are either ignoring AI search entirely or applying traditional SEO tactics without adapting them. The teams that understand the mechanics of retrieval augmented generation, entropy reduction, and citation behavior have a meaningful advantage.
That advantage will not last forever. As more practitioners understand these dynamics, the baseline for citation worthy content will rise. The time to build your AI search presence is now, while the frameworks are emerging and the competitive landscape is still forming.
Start with the fundamentals: structured content, topical depth, multi source presence, and factual density. Layer in monitoring and iteration. The brands that get this right will not just appear in AI search results. They will be the ones the models recommend.
FAQs
What are citations in AI search?
Citations in AI search are the source URLs that AI models like ChatGPT reference when generating responses to user queries. These citations link back to the web pages the model retrieved and used to inform its answer. They function as the model's way of attributing information to specific sources.
How does ChatGPT decide which brands to recommend?
ChatGPT uses real time web search for over 95% of B2B software queries, retrieves candidate pages, and generates responses from those results. Brands that appear in six or more cited URLs are approximately six times more likely to be recommended. Both the quantity of citing sources and the prominence of brand position within those sources drive recommendation probability.
Does domain authority matter for AI search?
Domain authority influences the retrieval stage because high authority sites tend to rank better in the Google results that ChatGPT pulls from. However, once content is retrieved, the model evaluates it based on structure, specificity, and relevance rather than domain reputation. Smaller sites with well structured, specific content can outperform high authority sites in the generation phase.
What is entropy reduction and why does it matter for AI search?
Entropy reduction describes how language models prioritize content that reduces uncertainty in their token prediction process. Content that presents information in clear, self contained, structured units is lower entropy and therefore more useful to the model. This makes structured lists, defined frameworks, and specific data points more likely to be cited than vague or rambling prose.
Does JSON LD or schema markup help content appear in AI search?
JSON LD and schema markup may assist with upstream retrieval by helping search systems categorize your content. However, there is no evidence that structured data directly influences the generation phase where the model decides what to cite. The model works with text content, not schema markup, when producing its response.
How do I optimize content for RAG (retrieval augmented generation)?
Optimize for two stages. For retrieval, target specific queries with focused pages and build presence across multiple domains. For citation, structure content with clear headings, self contained sections, concrete claims, and front loaded key points. Factual density with specific data and examples makes your content more valuable to the model.
What content format works best for AI search citations?
It depends on the query type. Categorical queries (lists, comparisons, recommendations) favor structured content like bullet points, tables, and comparison matrices. Relational queries (explanations, analysis, strategy) favor well structured narrative content with clear logical flow. Match your format to the type of question your audience asks.
How many pages do I need to earn AI search citations?
Research shows a threshold effect at approximately six cited URLs. Brands appearing in six or more sources that the model retrieves are dramatically more likely to be recommended. Focus on building a cluster of relevant pages across your own domain, guest posts, review sites, and industry publications.
Is optimizing for AI search different from traditional SEO?
The two overlap at the retrieval stage, where traditional ranking signals help your content enter the model's candidate set. They diverge at the generation stage, where content structure, factual density, and specificity matter more than link profiles or domain authority. An effective AI search strategy layers AI specific optimization on top of traditional SEO fundamentals.
How quickly is AI search behavior changing?
Very quickly. ChatGPT's web search usage rate jumped from 29% to 95.5% between October 2025 and early 2026. The models, retrieval pipelines, and citation patterns are evolving continuously. Monthly monitoring of your citation presence across key queries is the minimum cadence for staying current.