Proof of Importance: How LLMs Decide What to Cite
Your best performing page just became invisible.
Not demoted. Not outranked. Invisible. The content that drives 40% of your organic traffic doesn't exist in the answer your buyer actually sees.
This is already happening. Run your top commercial query through ChatGPT, then through Perplexity, then through Google's AI Mode. You'll see three different answers assembled from three different source sets. Your competitor appears in one. A Reddit thread appears in another.
You appear in none.
Same query. Three AI systems. Three different consensus views on who deserves to be cited.
Your content isn't competing for rankings anymore. It's competing to become a verified block in an AI's chain of reasoning. And each AI system runs its own consensus mechanism to decide which blocks make the cut.
One layer sits beneath all of this: training data. LLMs develop baseline "knowledge" during training, months or years before any user query. If your content appeared frequently in training data, the model already "knows" your information without needing to retrieve it. Dan Petrovic calls this "Primary Bias": brand associations the model holds before any retrieval happens.
Here's the uncomfortable truth: that game is already over. You can't retroactively get into GPT-4's training data. The incumbents who dominated authoritative sources when training data was scraped have a structural advantage baked into the model's weights. That door closed.
Which makes the retrieval layer the entire game for everyone else. You can't change what the model already knows. You can only compete on what it retrieves. The signals that follow aren't one path to visibility. For challenger brands, they're the only path.
The shift from traditional SEO to AI native visibility isn't a new channel to optimize. It's a fundamental restructuring of how information gets validated, assembled, and surfaced. The rules that built your organic traffic over the past decade don't apply to the interface where your buyers are increasingly starting their research.
Understanding how these consensus mechanisms work isn't optional anymore. It's the difference between contributing to AI responses and being excluded from them entirely.
The Unit of Competition Has Shrunk
In traditional search, you optimized pages. A page ranked. A page earned clicks. Domain authority lifted all your pages together. You thought in terms of "this page vs. that page" for position one.
In AI driven search, the unit of competition is smaller. It's not the page. It's the chunk. RAG systems typically chunk content into segments of a few hundred tokens, usually 256 to 512, before embedding and retrieval.
This isn't metaphor. It's how the architecture works.
When someone asks ChatGPT or Perplexity a question, the system doesn't retrieve your whole page and present it. It extracts a specific piece: a paragraph, a definition, a statistic, a comparison. That chunk gets evaluated on its own merits. Then it gets combined with chunks from other sources to assemble a composite answer.
Your 2,000 word guide might contribute exactly one paragraph to an AI's response. The rest? Invisible for that query. Meanwhile, a competitor's brief FAQ entry might contribute another paragraph. A Reddit comment might contribute a third. The user sees a synthesized answer built from pieces your page never "competed" against in traditional search.
The mechanics go deeper than chunking. Modern retrieval systems don't represent your content as a single point in vector space. They produce multiple embeddings per document, often one per token. Your page isn't a single vector. It's a set of vectors.
Scoring between a query and a document uses a function called Chamfer Similarity. For each query token embedding, the system finds the single best matching document token embedding. Then it sums those best matches across every query token. The final score reflects how well your content covers multiple dimensions of the query simultaneously.
This has a direct consequence. A document that strongly matches one aspect of a query but ignores three others will score lower than a document that moderately matches all four. Partial coverage across the full semantic field beats deep coverage on a single dimension.
Google Research published MUVERA in 2024, a multi-vector retrieval algorithm that compresses these sets of embeddings into fixed dimensional encodings for fast search. The system achieves 10% higher recall with 90% lower latency than prior approaches. Whether Google Search uses MUVERA specifically remains unconfirmed. But the retrieval paradigm it represents, multi-vector scoring across multiple query dimensions, is the direction the infrastructure is moving.
Your content doesn't compete as a page. It doesn't even compete as a chunk. It competes as a set of token-level embeddings scored across every dimension of the query.
This changes everything about how you think about content. A page can rank well in Google while being completely invisible to AI systems. Why? Because ranking and retrievability are different games. Ranking rewards comprehensive pages that satisfy intent. Retrieval rewards specific chunks that answer precise questions clearly and verifiably.
The best mental model comes from an unexpected place: blockchain consensus mechanisms.
In blockchain networks, no single node holds all the authority. Trust is distributed, and consensus is built from multiple verifications. AI search is moving toward the same structure: each source treated as a node, each chunk evaluated independently, authority decentralized from websites to individual content blocks.
The Consensus Mechanism: How AI Decides What Gets Included
If we're going to take the blockchain analogy seriously, we need to ask: what's the consensus mechanism? How does an AI actually decide which content blocks make it into the final answer?
It's not Proof of Work. The effort you put into creating content doesn't guarantee inclusion. Plenty of painstakingly crafted pages get ignored while a sparse forum thread gets quoted.
It's not simple Proof of Stake either. Domain authority matters, but a high authority site with irrelevant or vague content still gets passed over. You can't just accumulate reputation and coast.
The parallel is Proof of Importance (PoI), the consensus mechanism introduced by NEM in 2015. PoI was designed to solve a specific problem with Proof of Stake systems: in PoS, the more you hold, the more you earn. Capital accumulates passively. Stake once, coast forever.
PoI rejected this. Instead of rewarding holdings alone, it assigns each node an "importance score" calculated from multiple weighted signals: how much stake they hold, yes, but also who they transact with, their activity in the network, and their position in the relationship graph.
The "transaction partners" factor is particularly relevant: nodes that interact with other high importance nodes gain importance themselves. This is the same logic that powers PageRank. A link from an authoritative page carries more weight than a hundred links from unknown pages. Authority flows through the graph. It's recursive and relational, not absolute. You don't claim importance. It's conferred by those who already have it.
The parallel between PoI and AI search is direct. Domain authority is like stake: it matters, but you can't just accumulate it and coast. A high authority site with stale, vague content gets passed over. Importance requires ongoing participation, not just position.
Here's how this consensus mechanism actually operates at the technical level. RAG retrieval works similarly. When an AI assembles an answer, it's running a multi signal calculation on every potential content chunk.
Seven signals determine whether your chunk makes the cut. The first four establish baseline eligibility. The last three determine competitive advantage.
Signal 1: Structural Accessibility
Can the AI cleanly extract this information? This is not just an overlooked signal. It operates at a fundamentally different layer than the other six.
Modern retrieval systems run a multi-stage pipeline. The first stage is retrieval: selecting which content chunks even make it to the scoring phase. The later stages apply ranking signals like authority, evidence density, and corroboration. Structural accessibility determines whether your content passes that first gate.
A well structured chunk with clear formatting, logical headers, and self contained paragraphs is easier to retrieve than the same information buried in a wall of text. Your content might be relevant, authoritative, and evidence rich. But if it's structurally messy, the retrieval system may never surface it for scoring. The other six signals only matter for content that gets retrieved.
Structural accessibility is not one signal among seven. It is the prerequisite that makes the other six count.
Research on chunk boundary optimization shows that preserving semantic and sentence-level structure across chunk boundaries measurably improves retrieval and comprehension accuracy. Formatting that reflects logical structure is functional, not cosmetic.
Signal 2: Semantic Relevance
Does this chunk actually answer what the user asked? This isn't keyword matching. The AI understands intent. A chunk about "project management software pricing" won't surface for a query about "project management methodologies" even if both mention "project management." The semantic distance matters. Research on dense retrieval methods shows that embedding similarity consistently outperforms traditional keyword matching for complex queries.
The AI isn't scanning for terms. It's measuring conceptual distance in vector space.
And it's not measuring that distance as a single comparison. Multi-vector retrieval systems evaluate multiple partial matches between your content and the query. Each query token finds its best matching content token independently. A document scores well when it provides strong matches across several query dimensions, not just one.
This is why comprehensive topic coverage matters at a structural level. A page that precisely answers one sub-question but ignores adjacent questions will lose to a page that covers the full semantic field. Multi-intent coverage isn't a content strategy preference. It's a retrieval scoring mechanism.
Signal 3: Source Authority
What's the reputation of the domain this chunk comes from? This includes traditional signals like backlink profiles and domain age, but also newer signals: Is this source frequently cited by other sources the AI trusts? Does it appear in knowledge graphs? Has it been referenced in training data repeatedly? Google's AI Overview and AI Mode documentation explicitly lists "reliable and trustworthy sources" as a ranking factor. “Perplexity positions itself as a real-time answer engine with reliable source attribution,” heavily weighing source reliability in their retrieval pipeline.
Signal 4: Entity Relationships
How is this source connected to the entities in the query? If someone asks about "CRM software for startups," the AI maps the entities (CRM, software, startups) and evaluates which sources have strong, established relationships with those entities. A CRM vendor's own site has obvious entity relevance. But so does a startup focused publication that's written extensively about CRM tools. The relationship graph matters.
Research on entity-centric retrieval and knowledge-graph-enhanced RAG shows that modern AI systems decompose queries into entities and rank sources based on the strength of their relationships to those entities, not just keyword overlap. Documents that are deeply connected to query entities either as primary entities or as consistent, authoritative commentators are more likely to be retrieved and used in generation than sources with weak or superficial associations.
Signal 5: Evidence Density
Does this chunk contain verifiable specifics or just assertions? Research on RAG evaluation introduces evidence density as a key quality signal, showing that contexts rich in concrete, supporting facts consistently outperform vague or assertion-heavy passages in downstream question answering.
A paragraph stating “Our software improves productivity” carries far less weight than one stating “Our software reduced average task completion time by 23% across 500 enterprise users in a 2024 benchmark study,” because the latter provides dense, checkable evidence rather than unsupported claims.
Signal 6: Recency
When did this content last demonstrate relevance? For queries where freshness matters (pricing, features, industry trends, current events), older content gets systematically downweighted regardless of its other signal strengths. A 2023 comparison guide loses importance against a 2025 update, even if the older piece has stronger corroboration and authority signals.
This isn't uniform across query types. Evergreen topics (foundational concepts, established methodologies) face less recency pressure than dynamic ones (tool comparisons, market analysis, regulatory updates). But over 60% of commercial pages cited by ChatGPT were updated within the past six months. The AI treats publication and modification dates as trust signals: recent content suggests active maintenance and current accuracy.
Recency also interacts with corroboration. If the consensus view on a topic has evolved and your content still reflects the old consensus, you're not just outdated. You're now misaligned with what other trusted sources say, compounding the penalty.
Signal 7: Corroboration
Do other sources say similar things? This is where the consensus mechanism really kicks in. If your chunk claims something and three other trusted sources support that claim, your chunk's importance score increases. The effect intensifies as intent approaches purchase: 85% of brand mentions in AI responses for transactional prompts come from third party sources, not the brand's own domain. The AI systematically discounts self-promotion when users are ready to buy.
Research on knowledge conflicts in RAG systems shows models systematically prefer majority consensus when sources disagree. The more your claim aligns with what other trusted sources say, the higher your inclusion probability. If your chunk contradicts the consensus, it gets downweighted or excluded entirely.
The exception: if your source has exceptionally high authority signals, an outlier claim might still surface with hedging language ("According to [Source], though other sources suggest...")
When sources conflict, the system weighs authority against corroboration. A primary source (the vendor's own pricing page) beats a dated third party reference. An outlier claim with no corroboration gets excluded unless the source has overwhelming authority signals. When two credible sources genuinely disagree, the AI often hedges: "Some sources suggest X, while others note Y."
The principle: extraordinary claims require extraordinary corroboration. The more your content diverges from consensus, the more authority you need to earn inclusion.
These seven signals aren't equally addressable.
Start here (what you control entirely):
Evidence Density, Structural Accessibility, Recency. These improve retrievability immediately without waiting on external validation. You can fix these this week.
Build over time (what requires external validation):
Source Authority, Corroboration. These depend on other people citing you, linking to you, echoing your claims. They compound but take months to materially shift.
Ongoing discipline (what shapes everything you publish):
Semantic Relevance, Entity Relationships. These aren't one time fixes. They're editorial principles that should inform every piece of content going forward.
The Eighth Variable: Information Gain
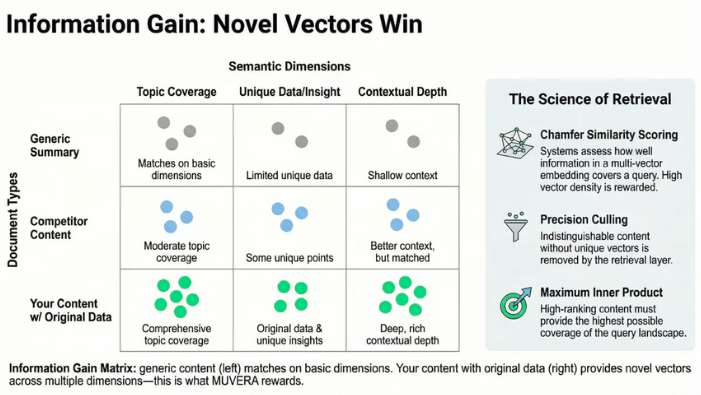
The seven signals describe how content gets evaluated. But there's a structural advantage that operates before evaluation begins: information gain.
Content that says the same thing as every other page on a topic produces token embeddings that cluster together in vector space. When multiple documents generate near-identical embeddings, retrieval systems treat them as substitutable. The document with the strongest authority signals wins. Everyone else gets filtered out.
Content that provides unique information produces embeddings that occupy distinct positions in vector space. Proprietary data. Named frameworks. Original research findings. These create token-level matches that no competitor document can replicate.
This is mathematically how Chamfer scoring rewards originality. Each unique data point, each proprietary finding, each named methodology produces an embedding that stands alone in the vector space. Generic summaries cluster with the competition. Unique evidence creates retrieval advantages that are independent of authority.
The practical implication: every page targeting AI citation should contain at least one claim, data point, or framework that cannot be found on any competing page. That element is your information gain. It's the embedding no other document can match.
This connects directly to the consensus calcification problem. First movers don't just get cited more. They create the embedding patterns that define what the category consensus looks like. Later entrants produce embeddings that look like echoes of the first mover's content. The retrieval system treats the original as the primary source and the echo as redundant.
If you want to break into a consensus that's already forming, generic content won't do it. You need information the consensus doesn't contain yet.
The Signals Aren't Weighted Equally Everywhere
The PoI framework describes where AI search is converging, not where every platform has fully arrived. Google AI Mode still leans on traditional ranking signals. ChatGPT's retrieval remains inconsistent. Perplexity is closest to the model in practice.
But the trajectory is clear. Every major update pushes toward multi signal evaluation, source corroboration, and chunk level retrieval. The platforms are converging on the same logic even if they're arriving at different speeds.
For now, each runs its own weighting system, and Goodie's study on elements impacting AI search visibility reveals just how different those weightings are:
Google Gemini
Scored highest of all platforms on Trustworthiness & Credibility, and not surprisingly, also led on Content Relevance. This tracks with Google's broader quality rater guidelines and their institutional obsession with EEAT.
ChatGPT
Weights Semantic Relevance and Evidence Density more aggressively. It prioritizes content that answers precisely, cites evidence, and connects entity relationships clearly. Who you are matters less than what you prove.
Perplexity
Positions its models around Source Attribution, Recency, and Structured Data. It's built for research use cases where users expect cited sources and current information. Stale content gets buried fast here. Your content refresh cadence matters more on Perplexity than anywhere else.
Claude
Places a similar emphasis on Trustworthiness to Gemini, while also having the most rigorous Data Verification mechanisms. Its emphasis on Localization and Contextual Relevance also exceeded that of the other models. If you're targeting international or niche audiences, Claude may surface your content where others won't.
Takeaway
Match your optimization priorities to where your ICP actually searches, not to "AI search" as a monolith. If your ICP researches purchases in Perplexity, your refresh cadence matters more than your backlink profile. If they're asking ChatGPT for recommendations, evidence density and entity mapping will move the needle faster than domain authority.
One layer beneath these platform differences is a structural distinction most practitioners miss. Retrieval and generation are separate pipeline stages with different signal requirements.
At the retrieval stage, all platforms converge on similar needs. Semantic relevance and structural accessibility gate what content gets surfaced. These signals are platform-agnostic. Content that fails retrieval on one platform likely fails on all of them.
At the generation stage, platform-specific weightings apply. Gemini leans on trustworthiness. ChatGPT weights evidence density. Perplexity prioritizes recency and source attribution. These differences matter for competitive positioning, but only for content that already passed retrieval.
This creates a clear optimization hierarchy. Fix retrieval-layer signals first. They unlock visibility everywhere. Then tune generation-layer signals for the platforms your ICP actually uses.
Grounding vs Citation: The Visibility Gap
Everything above describes how to get your content into the answer. But there's a harder question most people never ask: what kind of inclusion are you actually getting?
Not all visibility is equal. Your content can shape an AI's response without your brand ever appearing in it. You can influence thousands of answers and get zero credit. This is the visibility gap, and understanding it changes how you think about what "winning" in AI search actually means.
The distinction is grounding vs citation.
When an AI uses your content to inform its answer, that's grounding. When it explicitly names your source in the response, that's citation.
These aren't the same thing.
Your content might ground thousands of AI responses without ever being cited. The model absorbed your framing, your data, your perspective during training or retrieval, then presented it as synthesized knowledge without attribution. You influenced the answer. You got no visibility for it.
34% of Google Gemini and 24% of OpenAI GPT-4o responses are generated without explicitly fetching any online content.
Citation requires an additional threshold: the AI must judge that attributing the source adds value to the response. Typically this happens with specific claims, statistics, or quotes. General knowledge gets grounded but not cited.
There's a third possibility that's worse than invisibility: misrepresentation.
Google’s AI Mode doesn't feed full pages to Gemini. An extractive summarization algorithm scores chunks by relevance and shows only fragments to the model. On average, only around a third of your page content gets seen by Gemini.
The risk is real. Partial extraction can strip nuance, flatten complexity, or present conclusions without the caveats that qualified them. A balanced comparison becomes a one sided endorsement. A conditional recommendation becomes an absolute claim. Your brand gets cited for a position you didn't actually take.
Short, structured content blocks reduce this risk. When each chunk is self contained and meaning complete, there's less to lose in extraction. Long form documents with ideas that build across sections are more vulnerable to fragmentation that distorts the original intent.
The optimization implication: if you want citation (visible brand presence in AI responses), you need citable content. Specific data points, named frameworks, quotable definitions. Generic explanatory content gets grounded and forgotten. Distinctive, evidence dense content earns the citation.
One more complication: consensus isn't universal. Google's AI Mode explicitly uses personal context. Location, search history, interaction patterns. Two users asking the same question may receive different synthesized answers from different sources. A source might have high importance for enterprise buyers in fintech and low importance for SMB buyers in healthcare, even for similar queries.
This makes audience specificity more important, not less. Generic content that appeals to everyone may appeal strongly to no one's personalized context.
The question shifts from "How do I rank for this keyword?" to "How do I increase my importance score for the queries that matter?".
Understanding the difference between grounding and citation clarifies what you're optimizing for. The harder question is whether you still have time to build it.
Consensus Calcifies
The framework might suggest that importance, once built, persists indefinitely. It doesn't. And the window for building it is narrowing.
Your importance decays without maintenance.
Entity relationships drift. If your brand was strongly associated with "project management software" in 2023 but you've pivoted to "workflow automation" in 2025, your entity graph has lag. The AI's understanding of your brand trails your actual positioning until you rebuild those associations across platforms.
Competitors don't stand still either. Other sources are publishing new content, earning new citations, building their own importance scores. Static content doesn't maintain position. It loses position to active competitors filling the gap.
Maintenance cadence depends on category velocity. Fast moving categories (AI tools, crypto, trending tech) require quarterly content refreshes. Stable categories (compliance frameworks, established methodologies) can sustain importance for 12 months before decay becomes significant.
Over 70% of pages earning citations in ChatGPT were updated within the past 12 months. If your content refresh cycle is annual, you're already behind the median.
This mirrors the original Proof of Importance design: importance required continued network participation, not just accumulated stake.
But here's what most people miss: while you're maintaining, the consensus itself is hardening.
In traditional search, legacy domains had structural advantages that were nearly impossible to overcome. Fifteen years of backlinks. Thousands of indexed pages. Established domain authority. A site with that foundation could publish mediocre content and still outrank a newer competitor with better answers. The moat was cumulative.
AI search breaks that compounding effect. When an AI evaluates chunks for inclusion, your domain's backlink profile is one input among many, not the deciding factor. A well structured, evidence dense chunk from a Series A startup can beat a vague paragraph from an enterprise incumbent.
Authority metrics show declining correlation between traditional domain signals and AI citation rates.
But it comes with a tradeoff. In traditional search, you controlled your content. Your page was your page. The user saw what you wrote, in the context you designed, with your narrative framing intact.
In AI search, you contribute raw material. The AI decides what to extract, how to frame it, what to combine it with, which competing perspectives to place alongside it. Your content exists to serve the synthesis, not your narrative.
For challenger brands, this is the window.
But windows close. Research on AI citation patterns suggests position entrenchment: sources that appear for a query tend to persist over time. Models may develop preference for sources they've encountered repeatedly. The first movers in a category don't just get visibility. They help define what the AI treats as consensus.
The game is still open. But the consensus mechanisms are learning who the authoritative voices are in every category. Every month you wait, those patterns calcify further.
Get your blocks in.

This framework is the foundation of how we approach AI visibility for SaaS companies at Exalt Growth. If you want help applying it, we should talk.
Glossary:
Proof of Importance (PoI)
A consensus mechanism originally introduced by the NEM blockchain in 2015 that calculates node importance based on multiple weighted signals rather than stake alone. In this article, PoI serves as the conceptual model for how AI systems evaluate and select content for inclusion in generated responses. Unlike systems that reward accumulated authority alone, PoI requires ongoing participation and demonstrated relevance.
Chamfer Similarity
The scoring function used in multi-vector retrieval systems. For each query token embedding, Chamfer Similarity identifies the maximum similarity to any document token embedding, then sums those scores across all query tokens. Documents that provide strong matches across multiple dimensions of a query score higher than documents with a single strong match. Chamfer Similarity is the default scoring method in ColBERT-style late interaction models.
Chunking
The process of dividing source content into retrievable segments. Chunk boundaries significantly impact retrieval quality. Content that preserves semantic coherence across chunk boundaries performs better than content where key ideas are split between chunks.
Citation
When AI explicitly names your source in its response. Citation requires meeting a higher threshold than grounding: the AI must judge that attributing the source adds value to the response. Citations typically occur for specific claims, statistics, named frameworks, or direct quotes. Citation is the form of AI visibility that delivers brand awareness.
Consensus Mechanism
The method by which a distributed system reaches agreement on which information to trust and include. In blockchain networks, consensus mechanisms determine which transactions are valid. In AI search, the term describes how AI systems evaluate multiple sources and signals to determine which content chunks merit inclusion in a synthesized response.
Embedding
A numerical representation of text in high dimensional vector space. Embeddings capture semantic meaning, allowing AI systems to measure conceptual similarity between a query and potential source chunks. Two pieces of text with similar meanings will have embeddings that are close together in vector space, even if they use different words.
Entity
A distinct, identifiable concept, person, organization, place, or thing. In AI search, queries are decomposed into entities, and sources are evaluated based on their relationship strength to those entities.
Fixed Dimensional Encoding (FDE)
A compression technique introduced by Google Research's MUVERA paper that converts multi-vector representations into single fixed-length vectors. The dot product of two FDEs approximates the Chamfer Similarity between the original multi-vector sets. FDEs enable multi-vector retrieval at single-vector speed by reducing the computational cost by 90% while maintaining retrieval quality. The transformation is data-oblivious, meaning it works without knowledge of the specific dataset.
Grounding
When AI uses your content to inform or shape its response without explicitly attributing the source. Grounded content influences the answer but receives no visible credit. A significant portion of AI responses are generated using grounded information that is never cited to the user.
Importance Score
A composite evaluation of a content chunk's value based on multiple weighted signals. In the PoI framework, importance score determines whether content gets retrieved, used for grounding, and ultimately cited in AI responses. Importance score is dynamic and decays without ongoing maintenance.
Information Gain
The unique, non-replicable information a content chunk provides that cannot be found in competing documents. In retrieval systems, information gain creates token-level embeddings that occupy distinct positions in vector space, generating matches no competitor page can replicate. Proprietary data, named frameworks, and original research findings are high-information-gain elements. Generic summaries of widely available information produce low information gain because their embeddings cluster with every other document covering the same topic.
Multi-Vector Retrieval
A retrieval architecture where documents and queries are each represented as sets of token-level embeddings rather than single vectors. Multi-vector models like ColBERT generate one embedding per token, enabling richer semantic matching than single-vector approaches. Retrieval scores are computed via Chamfer Similarity, which evaluates partial matches across multiple dimensions of a query simultaneously. MUVERA, published by Google Research in 2024, introduced Fixed Dimensional Encodings to make multi-vector retrieval computationally efficient at scale.
Primary Bias
A term coined by Dan Petrovic describing brand associations and knowledge that LLMs hold from their training data, before any real-time retrieval occurs. Sources that appeared frequently and authoritatively in training data have structural advantages baked into model weights. Primary bias cannot be influenced retroactively for existing models.
RAG (Retrieval Augmented Generation)
An AI architecture that combines pre-trained language model capabilities with real-time information retrieval. Rather than relying solely on knowledge encoded during training, RAG systems search external sources, retrieve relevant content, and use that content to generate responses. RAG is the technical foundation enabling AI systems (like ChatGPT) to provide current, source-backed answers.
Vector Space
A mathematical space where text embeddings are positioned based on semantic meaning. Retrieval systems use vector space to find content chunks that are conceptually close to a user's query. Distance in vector space corresponds to semantic similarity, not keyword overlap.